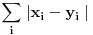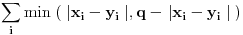Slicnost vectora/sekvenci
Slicnost vectora/sekvenciNa primer:
A=[1,4,5,6,7,2,1]
B=[1,4,5,0,0,0,1]
Prilozeni nizovi su prilicno slicni (razlikuju se u 3 unosa). Permutacija elemenata B si znacila manju slicnost, jer je poredjenje
po indexu (prvi s prvim, ...). Uzimanje u obzir unije, razlike,... bi znacilo zanemarivanje indexa. Isto, isti elementi na prvom, drugom, trecem,..
indexu bi zanemarivali absolutnu razliku; npr. B sa svim devetkama je blizi A nego B sa svim dvadeseticama.
Trenutno, slicnost izrazavam
sledecim:
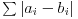
no, nisam siguran da je ovako jednostavna formula dovoljna da precizno odgovori koja je od 2 sekvence slicnija trecoj, jer, pored indexa,
zavisi i od magnitude.
Drugaciji predlozi su dobrodosli. Naravno, ukoliko se problem moze interpretirati linearnom algebrom, resenja cu uzeti u obzir.
Zahvaljujem