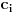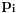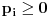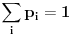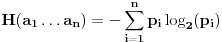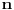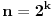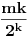Da ne bude da nisam odgovorio:
Citat:
atomant:
Ako te zanima kodiranje signala na osnovu entropije, pogledaj clanak na wikipediji o Hafmanovom kodu za kompresiju podataka bez gubitaka (JPEG i MPEG formati slike i videa koriste ovu vrstu kompresije, doduse rezultujuci video i slika imaju neke gubitke u informacijama ali one ne poticu od Hafmanovog koda vec od drugih koraka u kompresiji). PNG i GIF su looseless kompresije.
http://en.wikipedia.org/wiki/Huffman_coding
Uglavnom sta me zanima to i pitam. Tako da me zanimalo "kodiranje signala na osnovu
entropije" sigurno bih to i pitao. Hvala u svakom slucaju za sugestiju, verujem da je
iz najbolje namere, cituckao sam ja to i ranije, ali: ne vidim poentu?
I.) Iako na pocetku teksta zaista stoji da je Hafmanov kod "entropy encoding
algorithm":
In computer science and information theory, Huffman coding is an entropy encoding
algorithm used for lossless data compression.
ako pogledam kako se podaci koduju uz pomoc Hafmanovog koda tj. kako se gradi "Hafman tree"
1.)Create a leaf node for each symbol and add it to the priority queue.
2.)While there is more than one node in the queue:
- 1.)Remove the two nodes of highest priority (lowest probability) from the queue
- 2.)Create a new internal node with these two nodes as children and with probability
- equal to the sum of the two nodes' probabilities.
- 3.)Add the new node to the queue.
3.)The remaining node is the root node and the tree is complete.
nigde ne vidim entropiju kao meru ??? Da se primenjuje ili na bilo koji nacin ucestvuje?
Na osnovu broja pojavljivanja nekog simbola u poruci (ili predvidjenog broja pojavljivanja)
odredjuje se njegova verovatnoca, na osnovu verovatnoca pojavljivanja simbola odredjuju se
kodovi kojim ce ti simboli biti kodovani. Gde je tu entropija da bi kodovanje bilo
"na osnovu entropije"?
II.) Za primer koji sam naveo:
"zttttttttttttttztzztztttz"
izracunate su verovatnoce pojavljivanja simbola 'z' i 't':
p('z')=0.24 p('t')=0.76
In fact, a Huffman code corresponds closely to an arithmetic code where each of the
frequencies is rounded to a nearby power of ½ — for this reason Huffman deals relatively
poorly with distributions where symbols have frequencies far from a power of ½, such as
0.75 or 0.375. This includes most distributions where there are either a small numbers
of symbols (such as just the bits 0 and 1) or where one or two symbols dominate the rest.
III.)
Dosta ljudi je vec primetilo da se binarni signal koji se sastoji od z i t moze u
potpunosti zameniti nizom nula i jedinica sa istim rasporedom kao z i t. Te tako ulozivsi
neke resurse tek toliko da napravimo tabelu z=0, t=1 ili z=1, t=0 vec prema tome ko koje
slovo ili broj vise voli umesto pocetnog niza imacemo
"0111111111111110100101110" ili "1000000000000001011010001" gde ce p(0)=0.24, p(1)=0.76
(ili p(1)=0.24, p(0)=0.76):
For an alphabet {0, 1} with probabilities 0.625 and 0.375, Huffman encoding treats them
as though they had 0.5 probability each, assigning 1 bit to each value, which does not
achieve any compression over naive block encoding.
To jest niz 0011101... ce zameniti tim istim nizom 0011101...itd?
Mada ja mislim da bi i recenica:
"For an alphabet {z, t} with probabilities 0.625 and 0.375, Huffman encoding treats them
as though they had 0.5 probability each, assigning 1 bit to each value, which does not
achieve any compression over naive block encoding"
takodje bila tacna.
Prethodna 2 citata su preuzeta sa stranice:
http://en.wikipedia.org/wiki/Arithmetic_coding
Zasto bi onda trebalo da me zanima Hafmanovo kodiranje "za kompresiju podataka bez
gubitaka na osnovu entropije"?
Nemoj da pricas?




 Re: Entropija signala?
Re: Entropija signala?